First of all, I would like to say thank you all for loving this blog so much. As you are aware we have moved to "www.DataGenX.net" now. Keep Learning, Keep Sharing n Keep loving us :-)
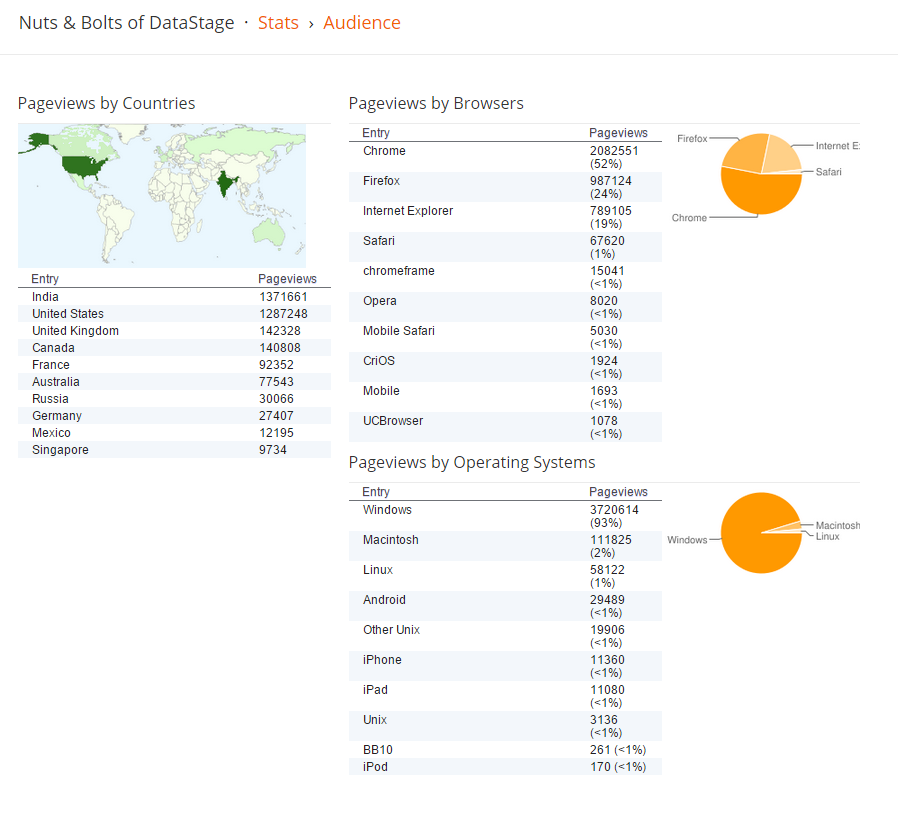
Today I am sharing Blog Report for "Nuts & Bolts of DataStage".


Like the Facebook Page & join Group
https://www.facebook.com/DataStage4you
https://www.facebook.com/groups/DataStage4you
https://twitter.com/datagenx
https://groups.google.com/d/forum/datagenx
For WHATSAPP group , drop a msg to 91-88-00-906098