Many times and Many places, this question is being asked :-) that How to delete the duplicate row from a table in different DBs. Here, we will see How to do this in DB2 DB.
Failed to authenticate
the current user against the selected Domain: Invalid user name (username)
or password.


:set list
:set nolist 






.jpg)
.jpg)
.jpg)
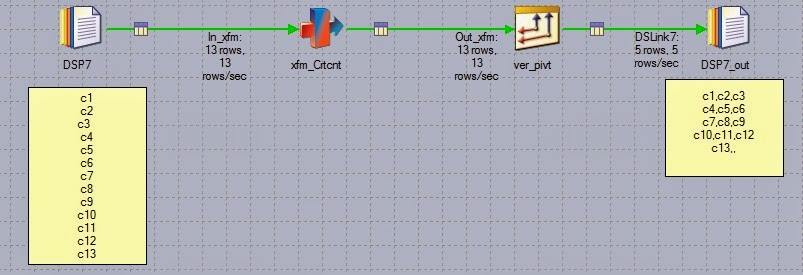

Input : source | destination | distance city1|city2|500 city2|city1|500 city3|city4|500 city4|city3|500
Input : Country|Currency|ValidFrom|ExRate CNH|USD|1-Jan-12|0.11 CNH|USD|5-Jan-12|0.8 CNH|USD|10-Jan-12|0.15 CNH|USD|15-Jan-12|0.14 CNH|USD|20-Jan-12|0.16
| col1 | col2 | col3 |
| a | {NULL} | b |
| f | k | {NULL} |
| h | {NULL} | n |
| i | d | {NULL} |
| {NULL} | s | {NULL} |
| g | u | m |
| l | x | o |
| m | {NULL} | {NULL} |
| c | d | z |


1st I/P file BRAND, MT, RE OV ,1 ,RE VG ,2 ,RE WU ,3, RE 2nd I/P file BRAND, MT, CX OV ,4, CX VG ,5, CX WU ,6, CX
Input : dept, emp ---------------------------- 20, R 10, A 10, D 20, P 10, B 10, C 20, Q 20, S

